Cloud-agnostique ou Cloud-natif ?
De mes échanges avec de nombreux acteurs de l’informatique ressort la crainte d’être enfermé chez leur fournisseur. Cette crainte est-elle fondée ? Que gagne t-on à être “cloud-agnostic” ? à être “cloud-native” ?
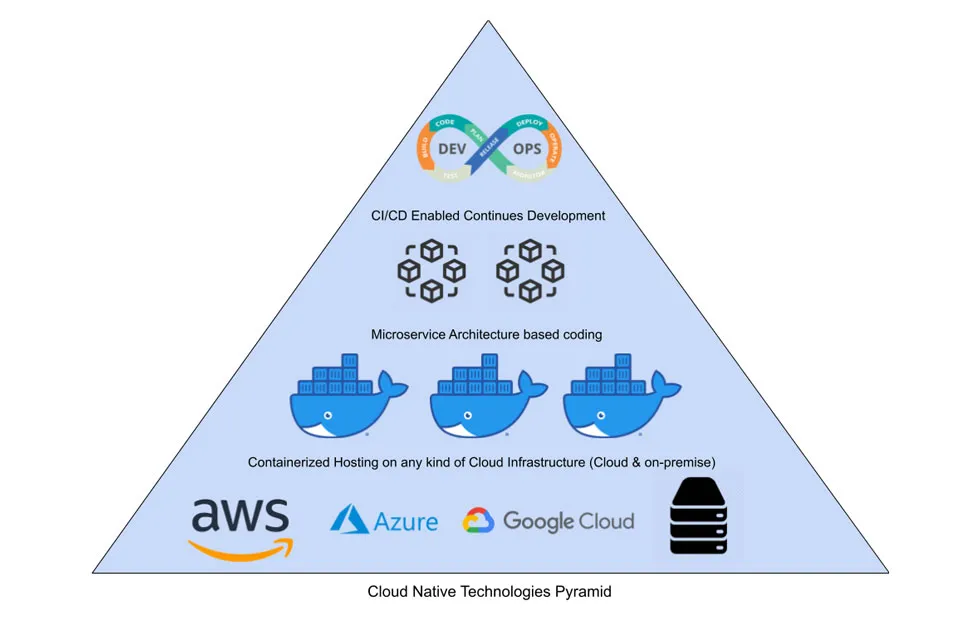
De l’importance de bien définir les termes
Une définition courante du terme “cloud-natif” est illustrée ci-dessus. Il s’agit d’applications qui, parce qu’elles s’appuient sur une architecture en micro-services et la conteneurisation, pourront tirer parti des capacités d’élasticité (scalabilité horizontale, notamment) d’un cloud.
C’est cette définition qui est poussée par la Cloud Native Computing Foundation, qui regroupe une galaxie d’éditeurs trouvant intérêt à cette définition (qui leur permet de caser leur produit).
Dans les faits, cette définition ne s’oppose pas frontalement à celle de cloud-agnostique : l’orchestration de conteneurs, souvent avec Kubernetes, permettra de faire tourner l’application sur n’importe quel cloud ou bien même sur site.
L’avantage principal de ces solutions cloud-agnostiques (outre la possibilité de changer de cloud provider) est la simplification du setup du poste de développement (il suffit de lancer Docker).
L’exploitation de ces solutions est beaucoup moins aisée : outre que Kubernetes est réputé extrêmement difficile à paramétrer pour répondre à un cahier des charges exigeant, les composants (reverse proxy, broker, moteurs de base de données, ) hébergés dans les conteneurs resteront à gérer, leurs interactions à sécuriser, etc. ce qui représente une charge considérable.
Bien sûr, il est toujours possible avec Ingress de déployer un Load Balancer managé plutôt qu’un controller Nginx, mais dans ce cas, on rajoute à la compréhension de ce qu’est un Load Balancer la sur-couche liée à l’API Ingress, et on perd le bénéfice d’avoir un poste de développement iso-prod.
Une autre définition de Cloud natif
Les cloud publics comme AWS ne permettent pas seulement de déployer des machines virtuelles ou des conteneurs à la demande, charge à l’utilisateur de manager leur contenu.
Un certain nombre de services permettent aussi de déléguer au cloud provider la gestion du système d’exploitation, voire de composants open source (comme un cluster PostgreSQL, un broker RabbitMQ, ou un service de streaming comme Apache Kafka).
- Ainsi, il devient possible d’utiliser des services sans forcément posséder toutes les compétences nécessaires à leur exploitation.
Ils offrent également des composants de plus haut niveau (en général faits “maison”), comme le bus d’événement EventBridge, le service de téléphonie Amazon Contact, des services d’IA comme Rekognition qui permet de faire de la reconnaissance d’image, des bases de donnés spécifiques (clé-valeur comme DynamoDB, ou de séries temporelles comme Timestream).
Ces services présentent de nombreux avantages :
- Ils ne nécessitent aucun administration.
- La gestion de la scalabilité est en built-in, supprimant complètement la nécessité de prévoir la charge sur l’application.
- Ils sont pour un certain nombre facturés à l’usage réel (ex. au nombre de millions de requêtes pour API Gateway) et plus à l’heure d’utilisation.
- La gestion de permissions est intégrée à l’Identity and Access Management (IAM) du cloud provider.
C’est le recours à ces services qui permettra de pleinement réaliser la valeur du cloud.
A titre d’exemple, des applications d’espace clients d’un fournisseur d’électricité, s’appuyant sur une telle stack server-less, “vraiment” cloud-native, représentent un coût d’hébergement inférieur à $30par mois.. et ni le fournisseur ni ses clients n’ont été impacté (ils ne l’ont même pas réalisé) quand l’application a subi récemment une tentative d’attaque DDOS.
Mais alors, ne faut-il pas craindre le “vendor lock-in” ?
Le terme “vendor lock-in” laisse penser que le cloud provider fait un effort délibéré pour nous empêcher soit d’utiliser des outils tiers soit de récupérer nos données pour changer de fournisseurs. Ce n’est le cas d’aucun des fournisseurs de cloud public.
Plutôt que parler de “vendor lock-in”, il conviendrait donc de parler plutôt de coût de réversibilité. Tout choix de technologie entraîne un temps d’appropriation, qui sera perdu, et l’écriture d’une certaine base de code, qui pourra nécessiter des modifications, parfois structurelles, en cas de décision radicale de sortie de cette technologie.
Mais surtout En outre, pour en sortir… il faudra faire l’effort que cette technologie nous a épargnés jusqu’ici ! On s’est épargné un DBA en s’appuyant sur RDS ? Pas sûr que notre base de données self-managée se comportera aussi bien, ou qu’on saura en extraire aisément les longest-running queries.
Quand — et comment — passer sur du “vrai” cloud-natif ?
Le début d’un projet sont le moment idoine pour poser des choix structurants ; les poser plus tard, c’est devoir supporter les coûts de réversibilité — qui ne sont pas à sens unique — évoqués ci-dessus !
Cependant, il peut être difficile ou insécurisant d’envisager des choix radicaux, comme une stack server-less, quand aucun développeur dans l’équipe n’a ce genre d’expérience et que les ops se définissent par leur capacité à administrer un OS Linux. Difficile alors de s’engager sur un cahier des charges ou un time-to-market.
Faites-vous accompagner ! Avec TerraCloud, j’accompagne les équipes tech des éditeurs et DSI à concevoir et déployer leurs solutions dans le cloud. Je serai heureux de vous aider à franchir la marche pour bénéficier des atouts d’une “vraie” stack “cloud-native”.